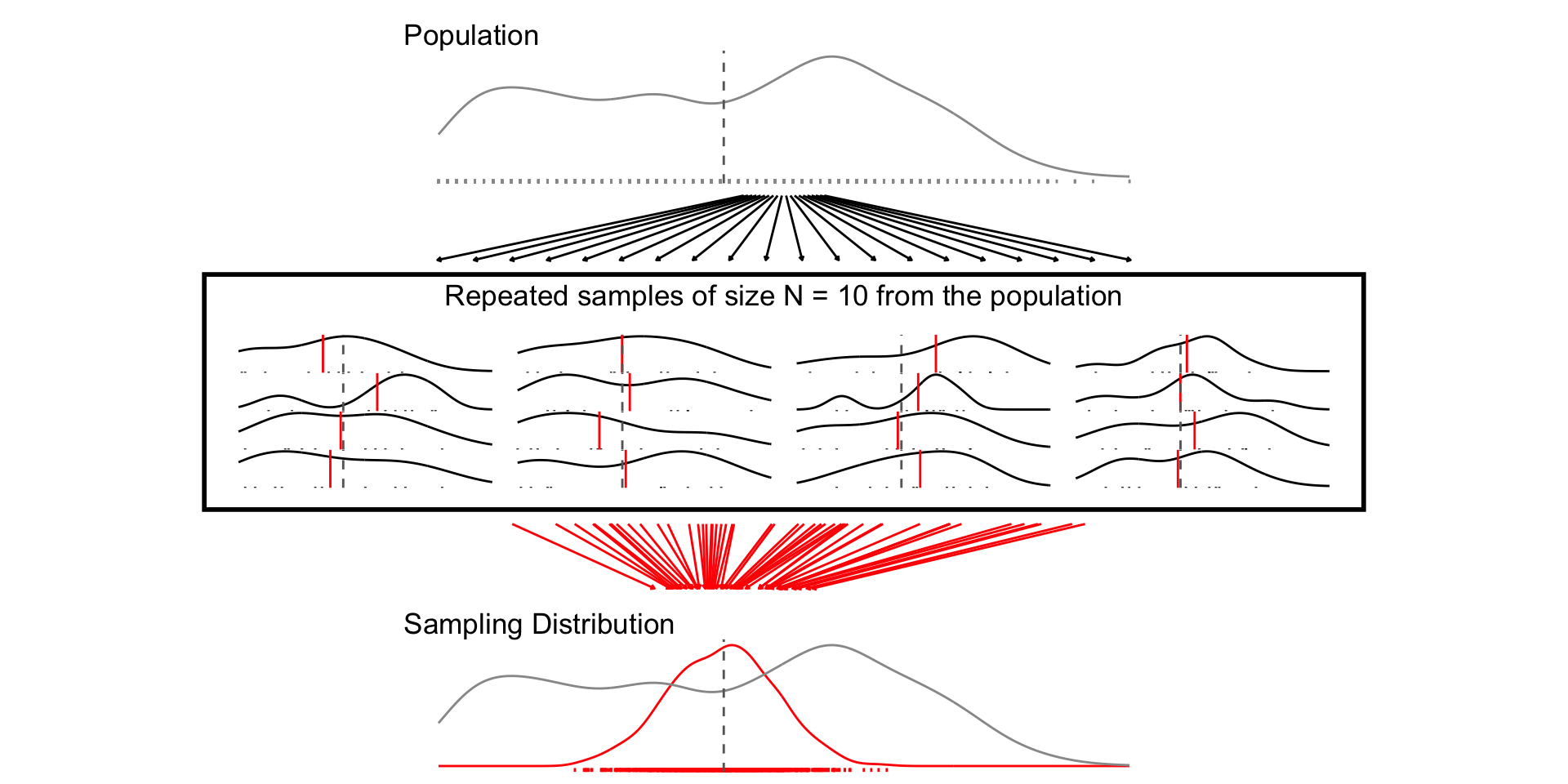
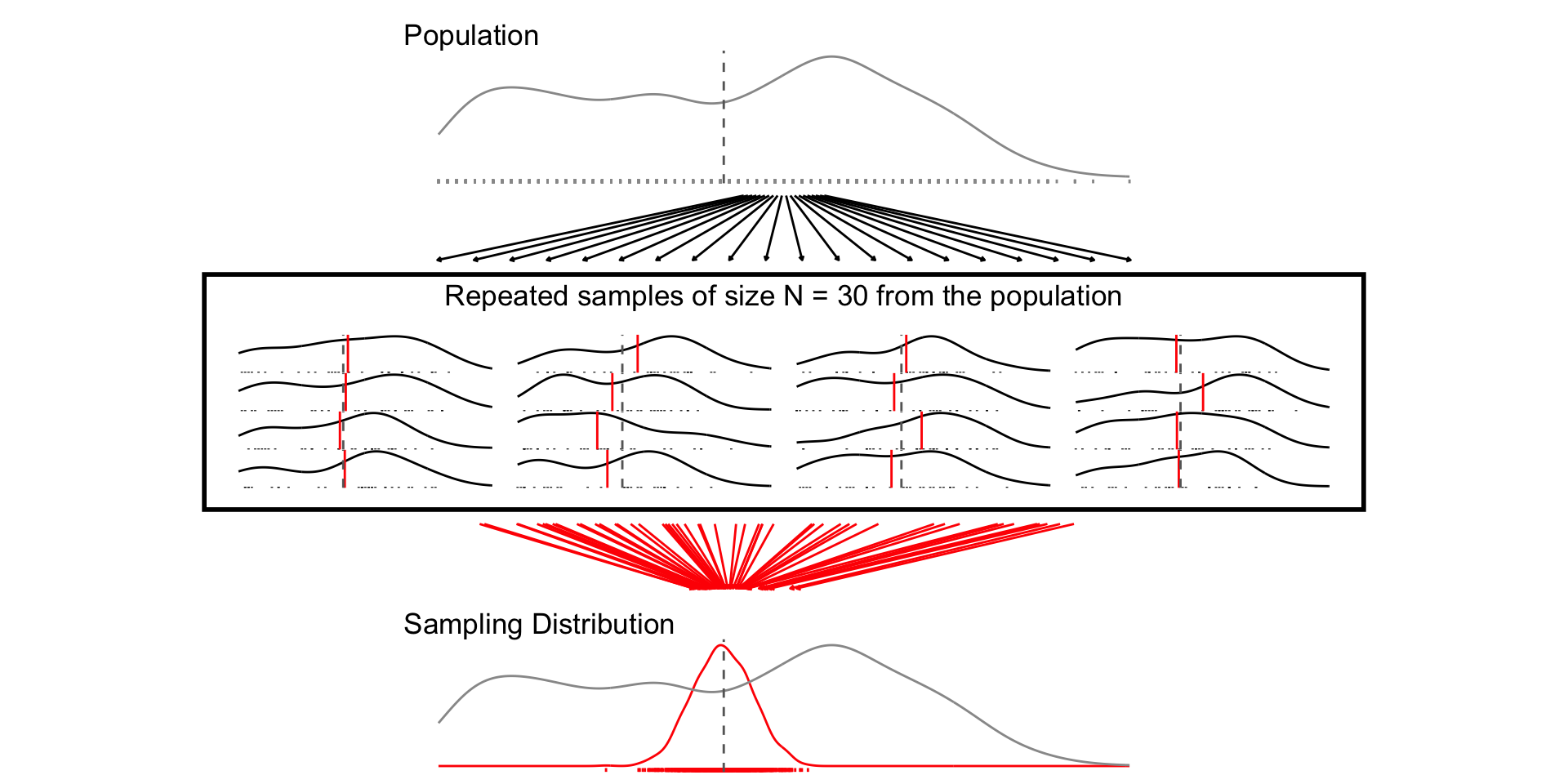
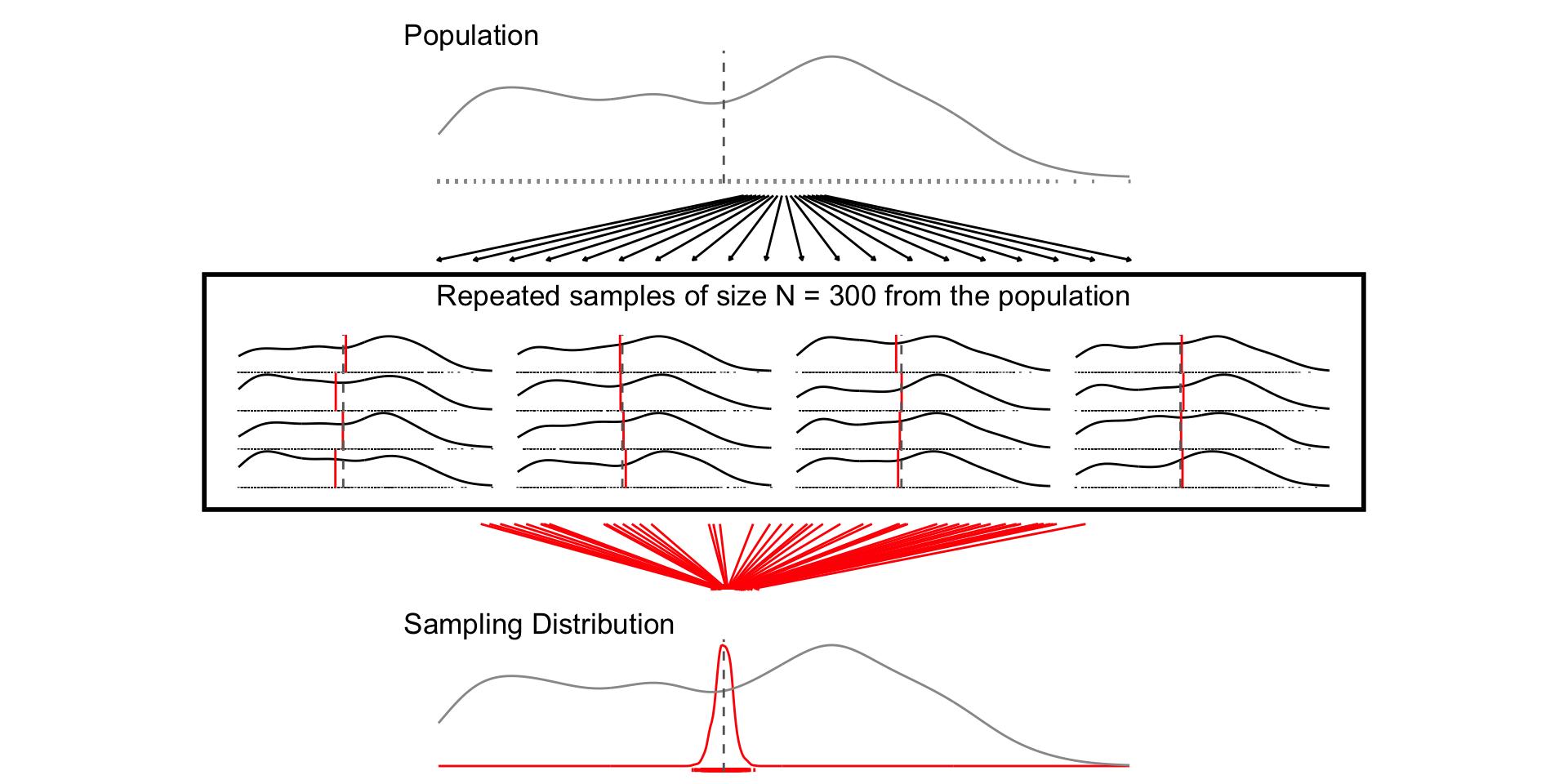
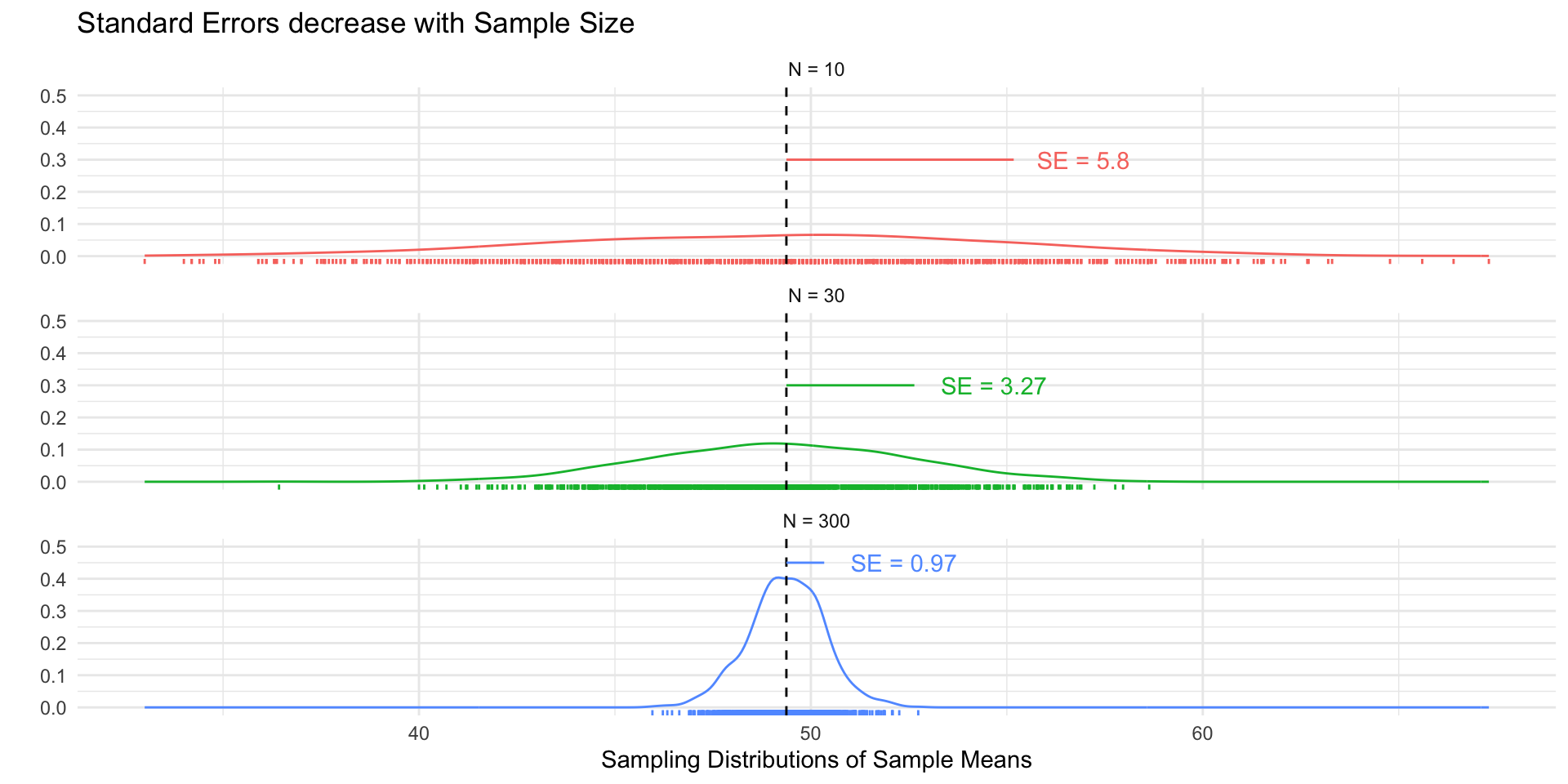
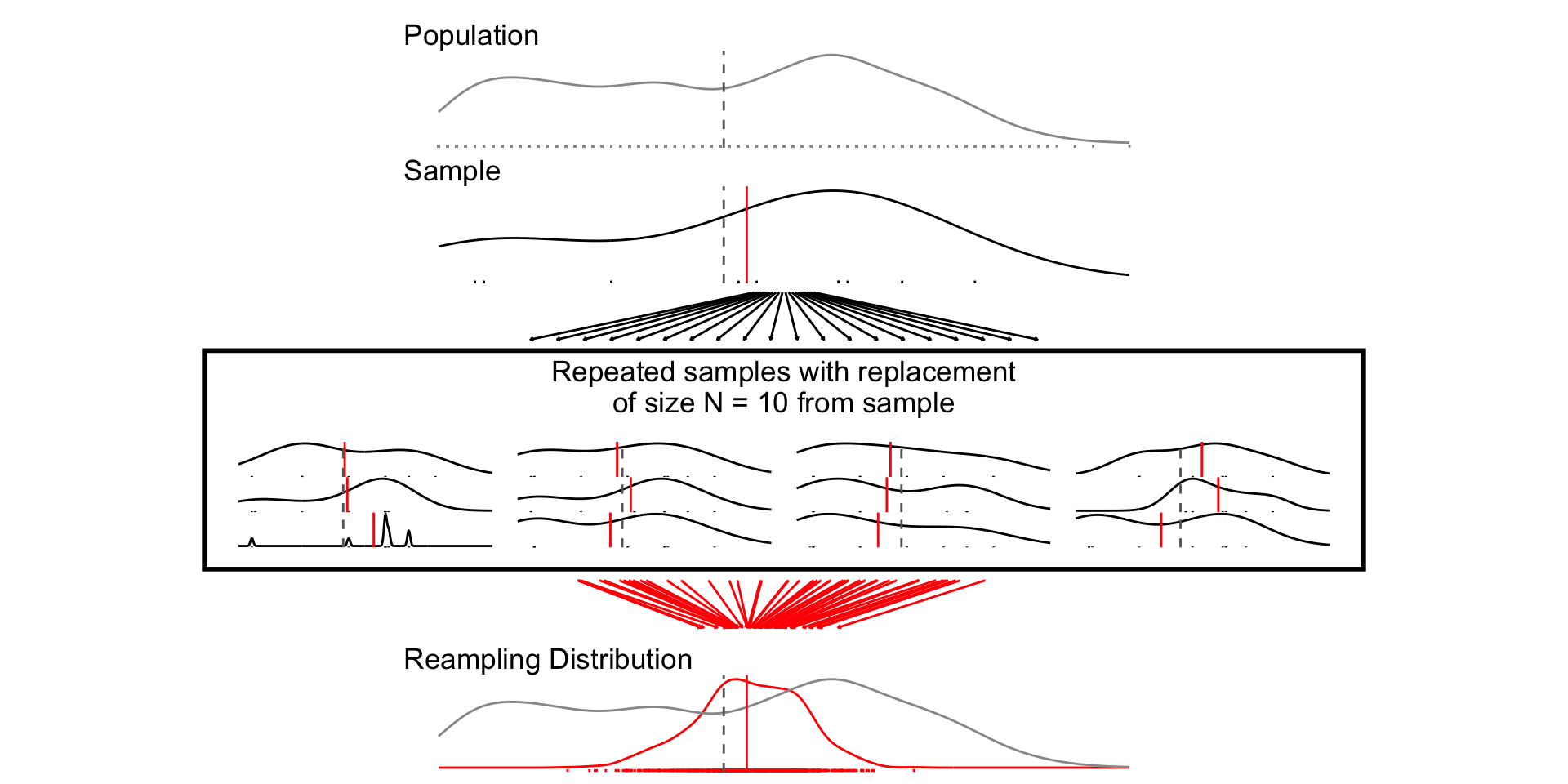
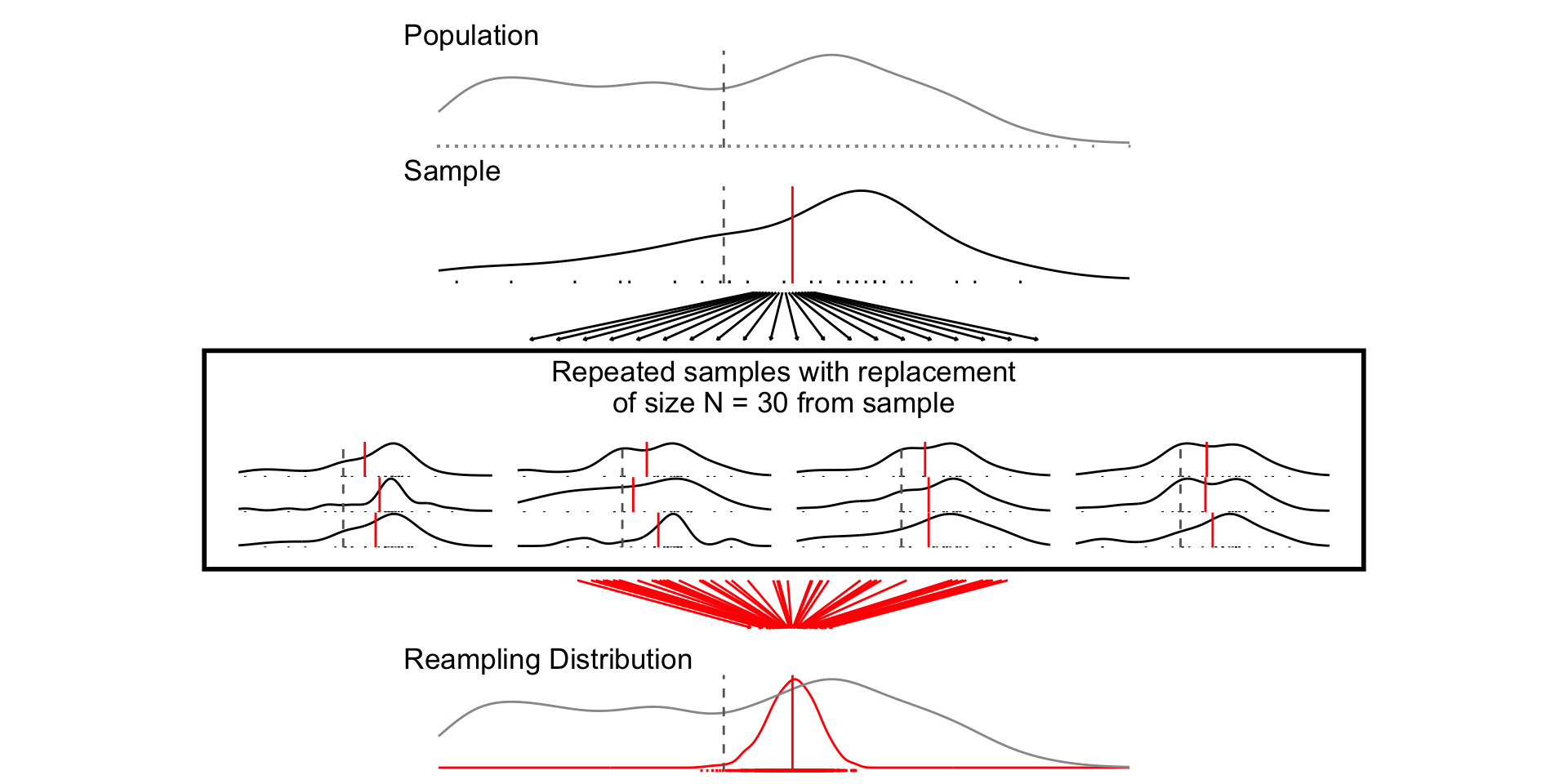
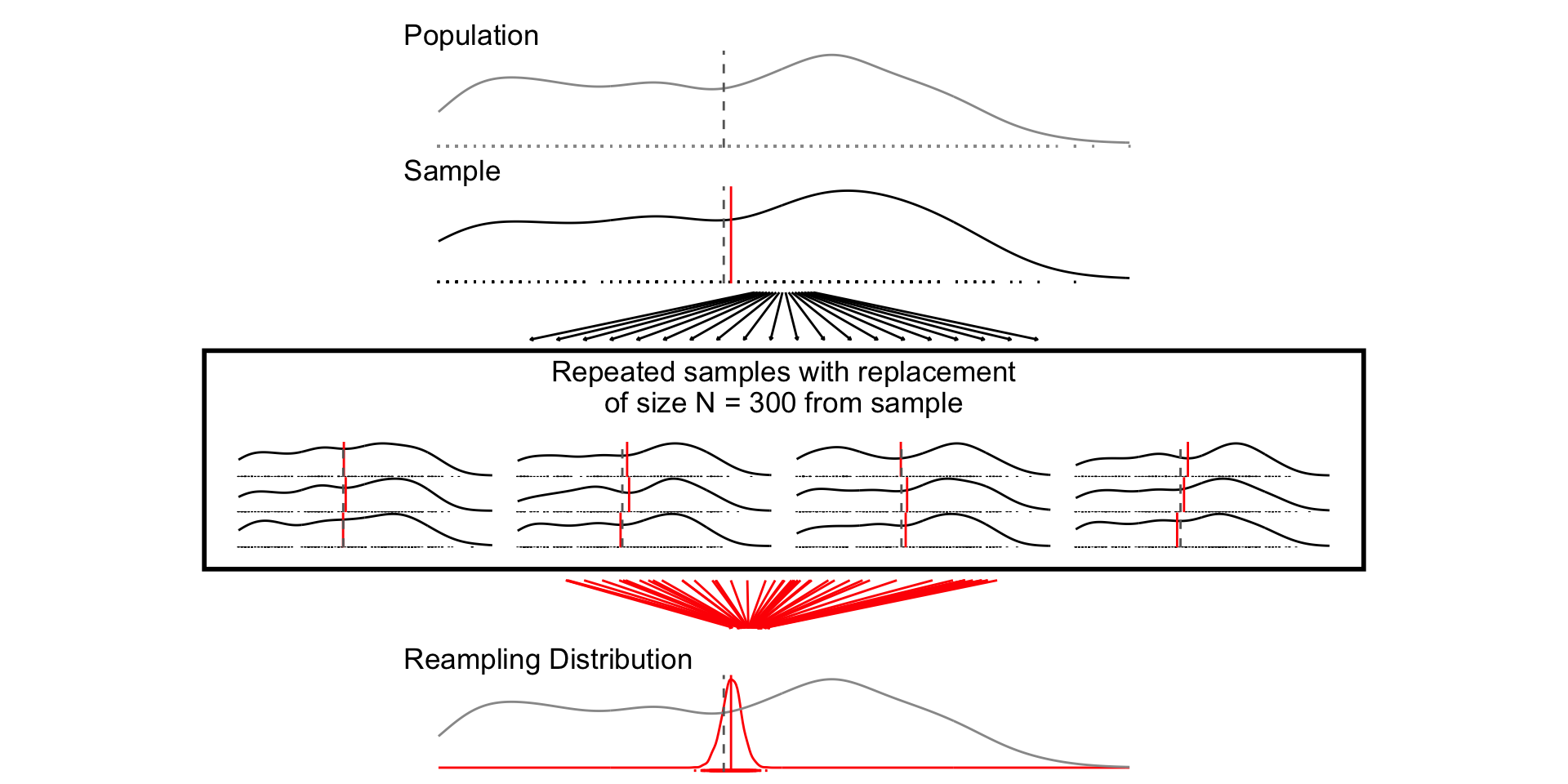
A sampling distribution is a theoretical distribution of estimates obtained in repeated sampling
What could have happened?
A standard error (SE) is the standard deviation of the sampling distribution
We can calculate SEs via simulation and analytically
We can use SEs to construct confidence intervals and conduct hypothesis tests allowing us to quantify uncertainty
Sampling distributions and standard errors
Populations and samples
Population: All the cases from which you could have sampled
Parameter: A quantity or quantities of interest often generically called \(\theta\) (“theta”). What we want to learn about our population
Sample: A (random) draw of observations from that population
Sample Size: The number of observations in your draw (without replacement)
Estimators, estimates, and statistics
Estimator: A rule for calculating an estimate of our parameter of interest.
Estimate: The value produced by some estimator for some parameter from some data. Often called \(\hat{\theta}\)
Unbiased estimators:\(E(\hat{\theta})=E(\theta)\) On average, the estimates produced by some estimator will be centered around the truth
Consistent estimates:\(\lim_{n\to \infty} \hat{\theta}_N = \theta\) As the sample size increases, the estimates from an estimator converge in probability to the parameter value
Statistic: A summary of the data (mean, regression coefficient, \(R^2\)). An estimator without a specified target of inference
Distrubtions and standard errors
Sampling Distribution: How some estimate would vary if you took repeated samples from the population
Standard Error: The standard deviation of the sampling distribution
Resampling Distribution: How some estimate would vary if you took repeated samples from your sample WITH REPLACEMENT
“Sampling from our sample, as the sample was sampled from the population.”
provide a way of quantifying uncertainty about estimates
describe a range of plausible values for an estimate
are a function of the standard error of the estimate, and the a critical value determined by \(\alpha\), which describes the degree of confidence we want
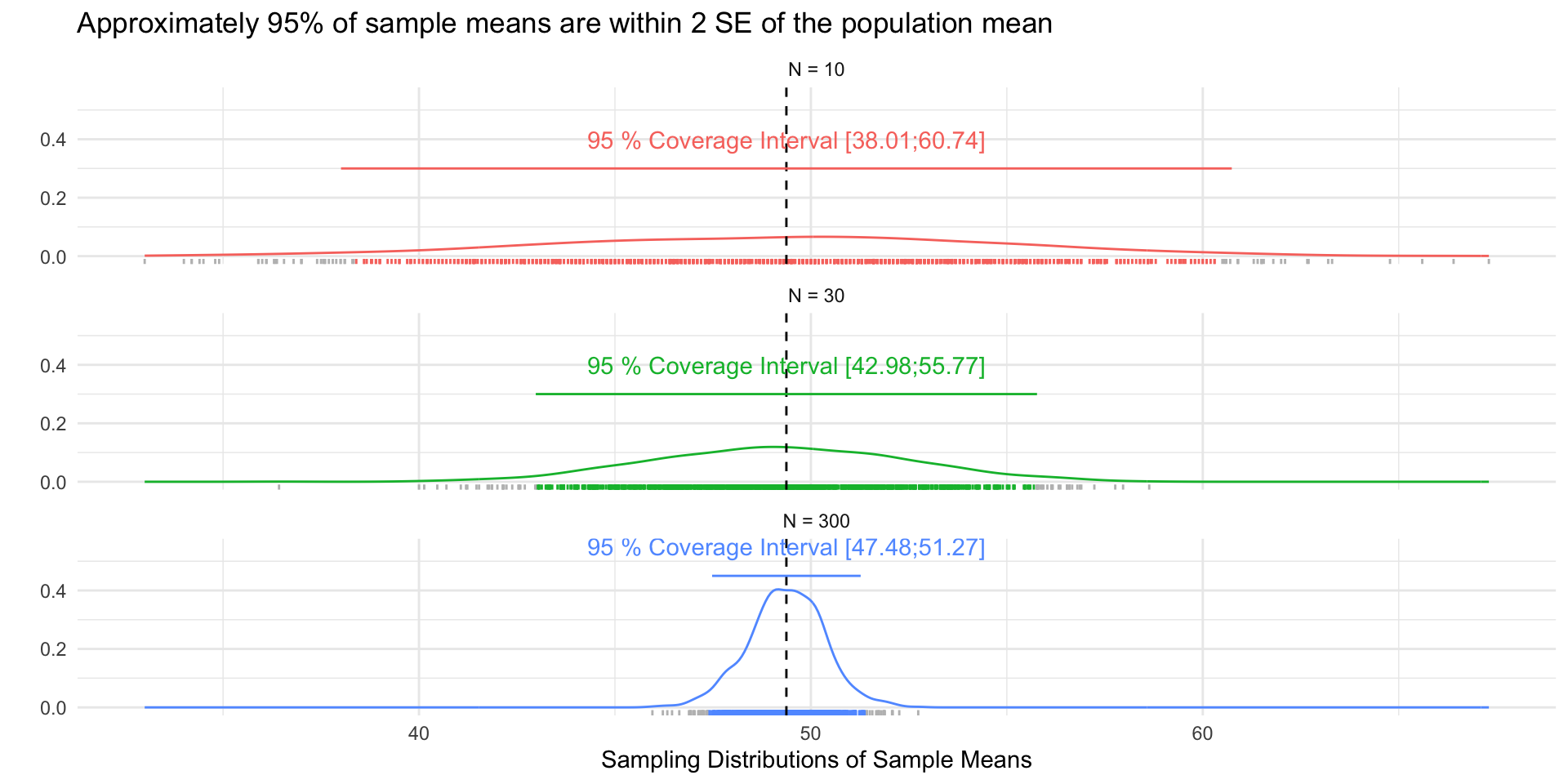
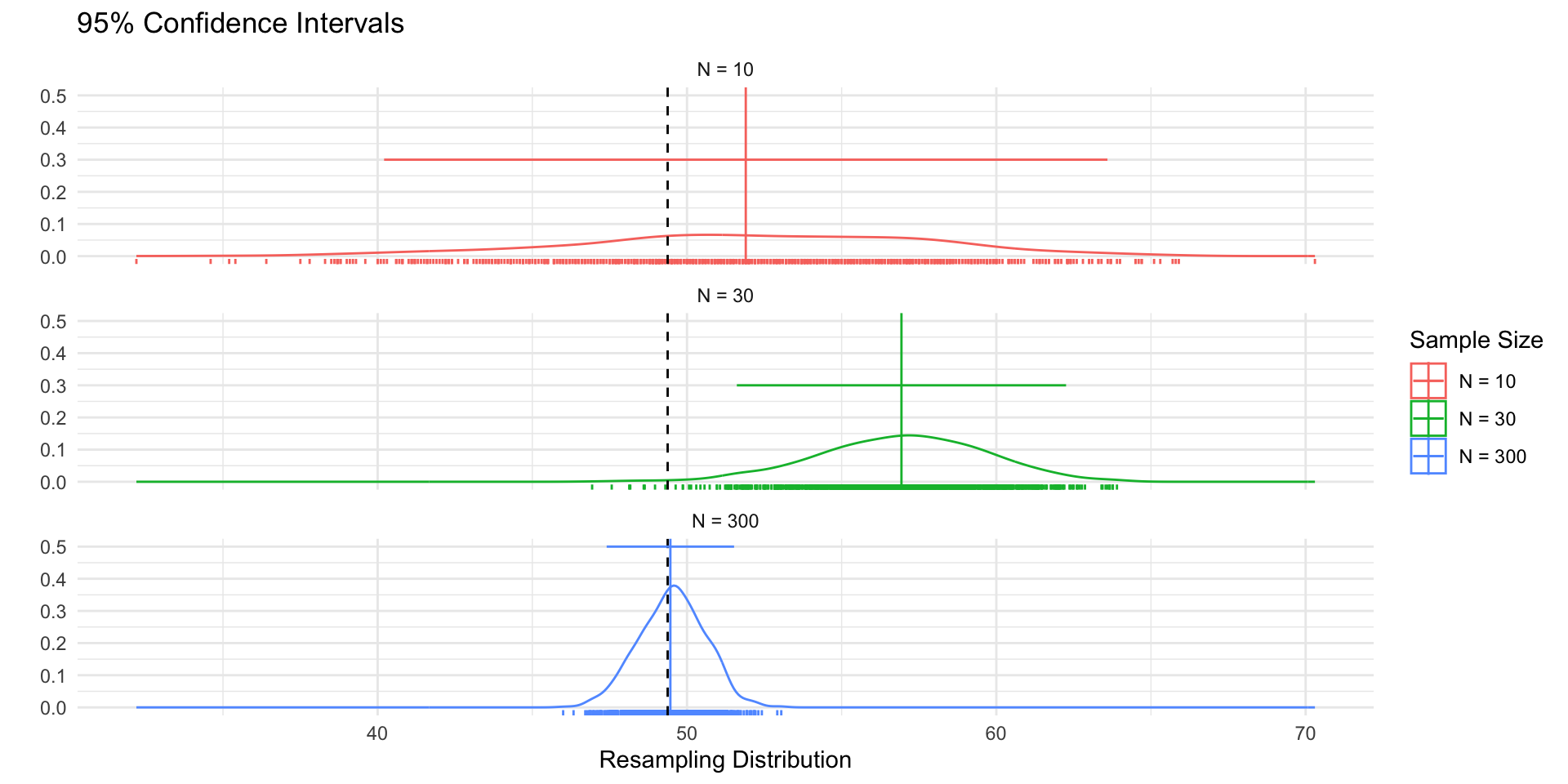
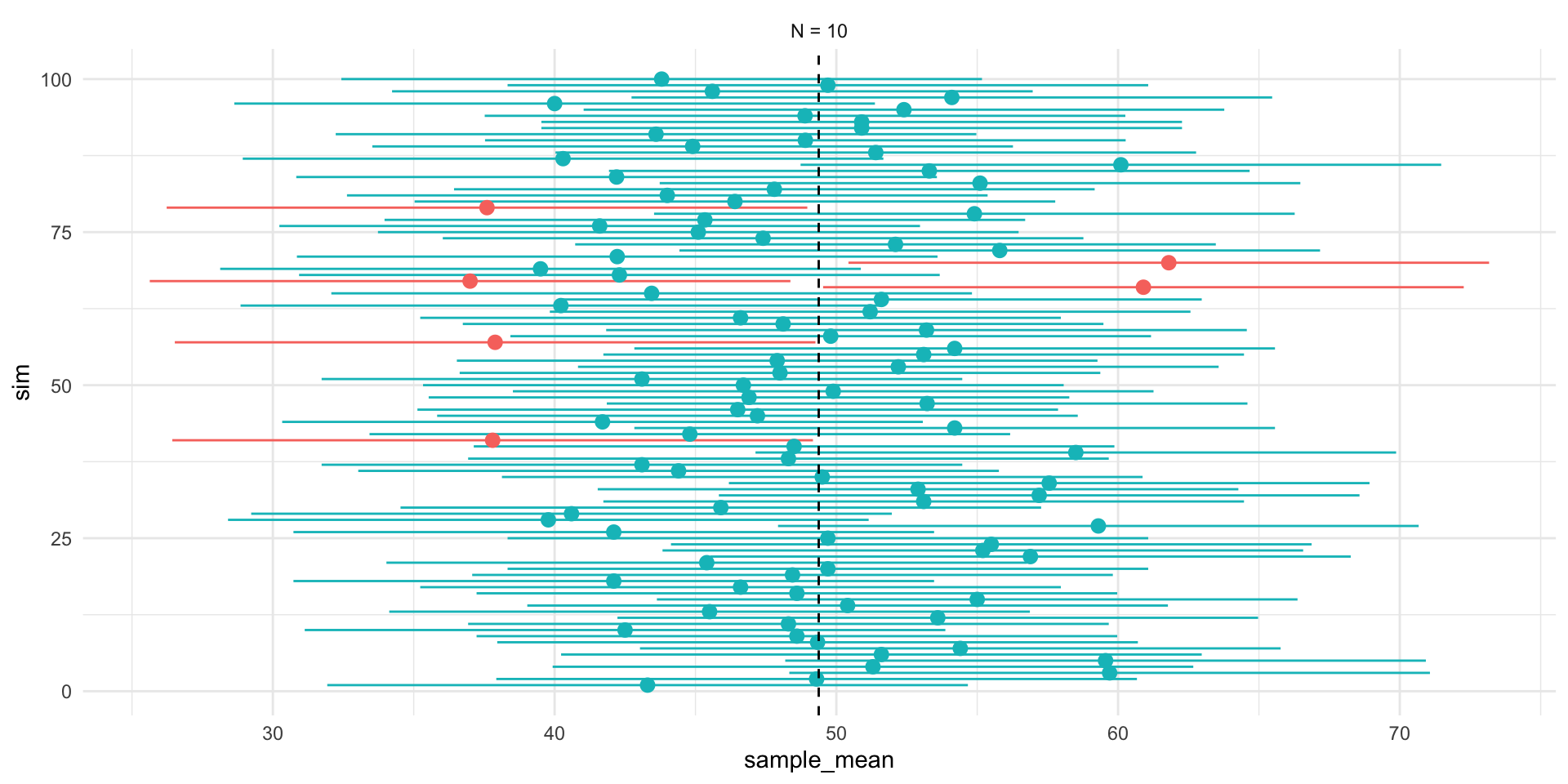
Figure 1 shows 3 confidences intervals for 3 samples of different sizes (N = 10, 30, 300). The CIs for N = 10 and N = 300, intervals contain the truth (include the population mean). By chance, the CI for N=30 falls outside of the truth.
Figure 2 shows that our confidence is about the property of the interval. Over repeated sampling, 95% of the intervals would contain the truth, 5% percent would not.
In any one sample, the population parameter either is or is not within the interval.
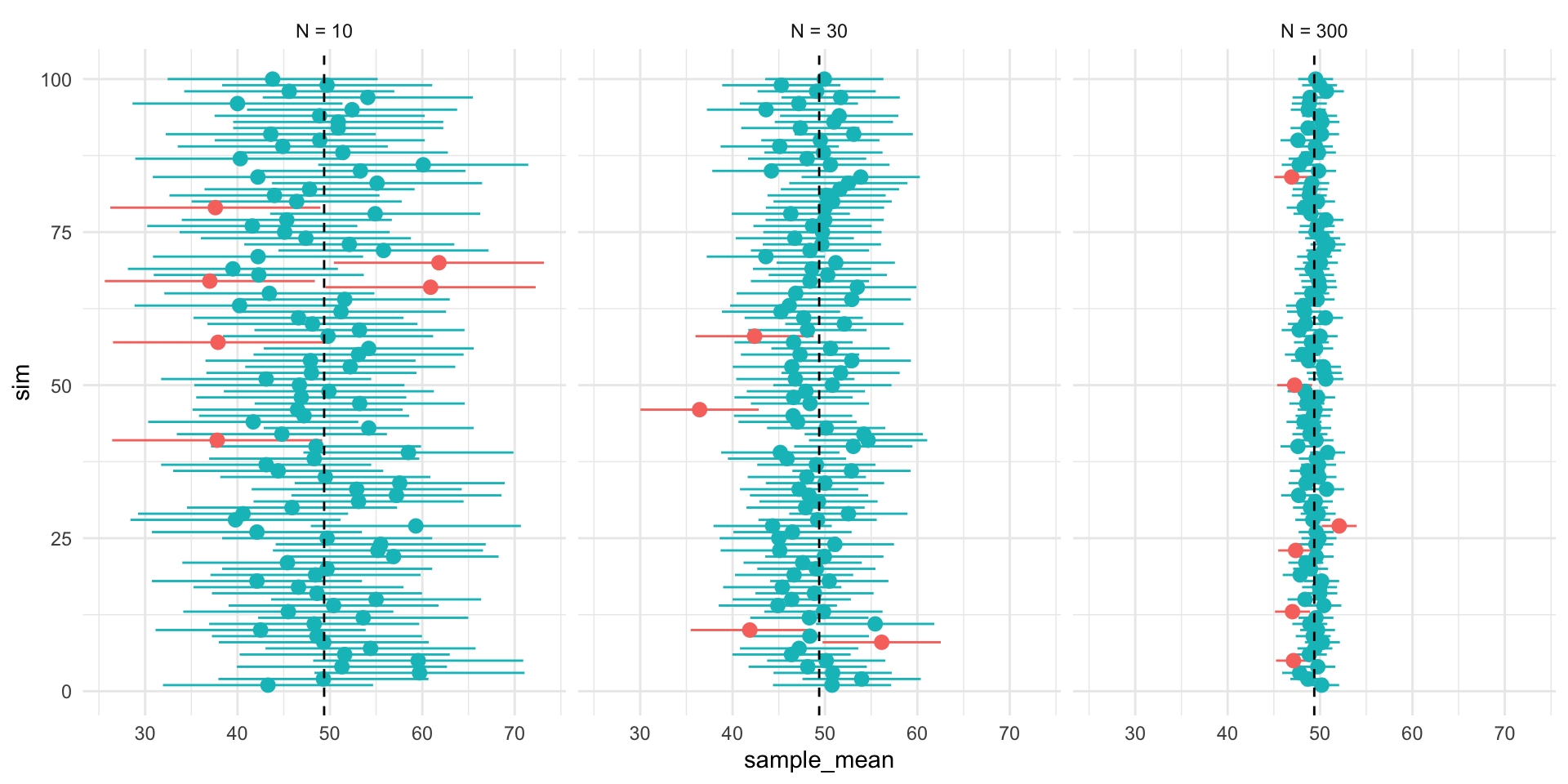
Figure 3, shows that while the width of the interval declines with the sample size, the coverage properties remains the same.
Interpreting confidence intervals
Confidence intervals give a range of values that are likely to include the true value of the parameter \(\theta\) with probability \((1-\alpha) \times 100\%\)
\(\alpha = 0.05\) corresponds to a “95-percent confidence interval”
Our “confidence” is about the interval
In repeated sampling, we expect that \((1-\alpha) \times 100\%\) of the intervals we construct would contain the truth.
For any one interval, the truth, \(\theta\), either falls within in the lower and upper bounds of the interval or it does not.
Hypothesis testing
What is a hypothesis test
A formal way of assessing statistical evidence. Combines
Deductive reasoning distribution of a test statistic, if the a null hypothesis were true
Inductive reasoning based on the test statistic we observed, how likely is it that we would observe it if the null were true?
What is a test statistic?
A way of summarizing data
difference of means
coefficients from a linear model
coefficients from a linear model divided by their standard errors
Different test statistics may be more or less appropriate depending on your data and questions.
What is a null hypothesis?
A statement about the world
Only interesting if we reject it
Would yield a distribution of test statistics under the null
Typically something like “X has no effect on Y” (Null = no effect)
Never accept the null can only reject
What is a p-value?
A p-value is a conditional probability summarizing the likelihood of observing a test statistic as far from our hypothesis or farther, if our hypothesis were true.
How do we do hypothesis testing?
Posit a hypothesis (e.g. \(\beta = 0\))
Calculate the test statistic (e.g. \((\hat{\beta}-\beta)/se_\beta\))
Derive the distribution of the test statistic under the null via simulation or asymptotic theory
Compare the test statistic to the distribution under the null
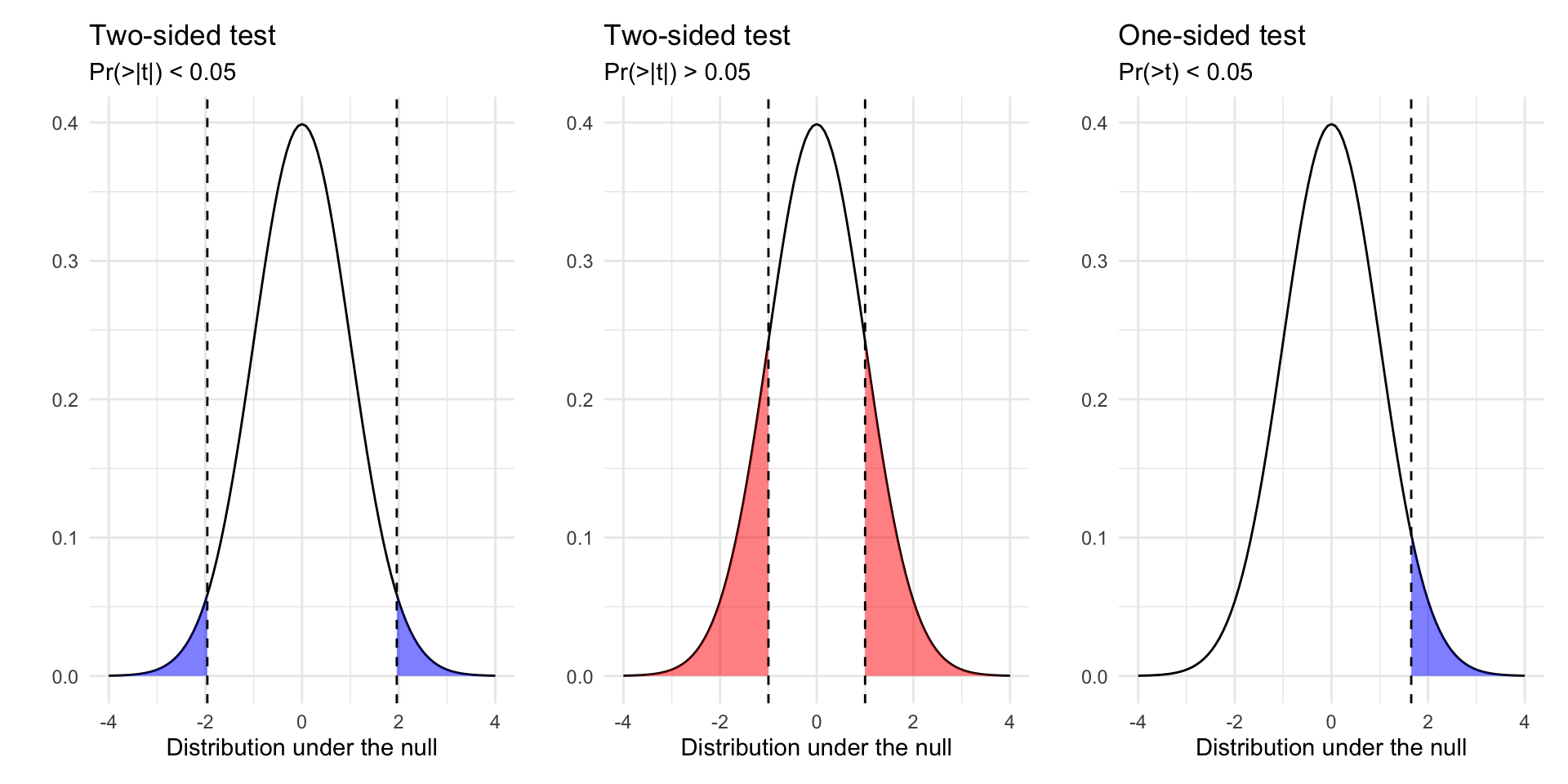
Calculate p-value (Two Sided vs One sided tests)
Reject or fail to reject/retain our hypothesis based on some threshold of statistical significance (e.g. p < 0.05)
Outcomes of hypothesis tests
Two conclusions from of a hypothesis test: we can reject or fail to reject a hypothesis test.
We never “accept” a hypothesis, since there are, in theory, an infinite number of other hypotheses we could have tested.
Our decision can produce four outcomes and two types of error:
Reject \(H_0\)
Fail to Reject \(H_0\)
\(H_0\) is true
False Positive
Correct!
\(H_0\) is false
Correct!
False Negative
Type 1 Errors: False Positive Rate (p < 0.05)
Type 2 Errors: False negative rate (1 - Power of test)
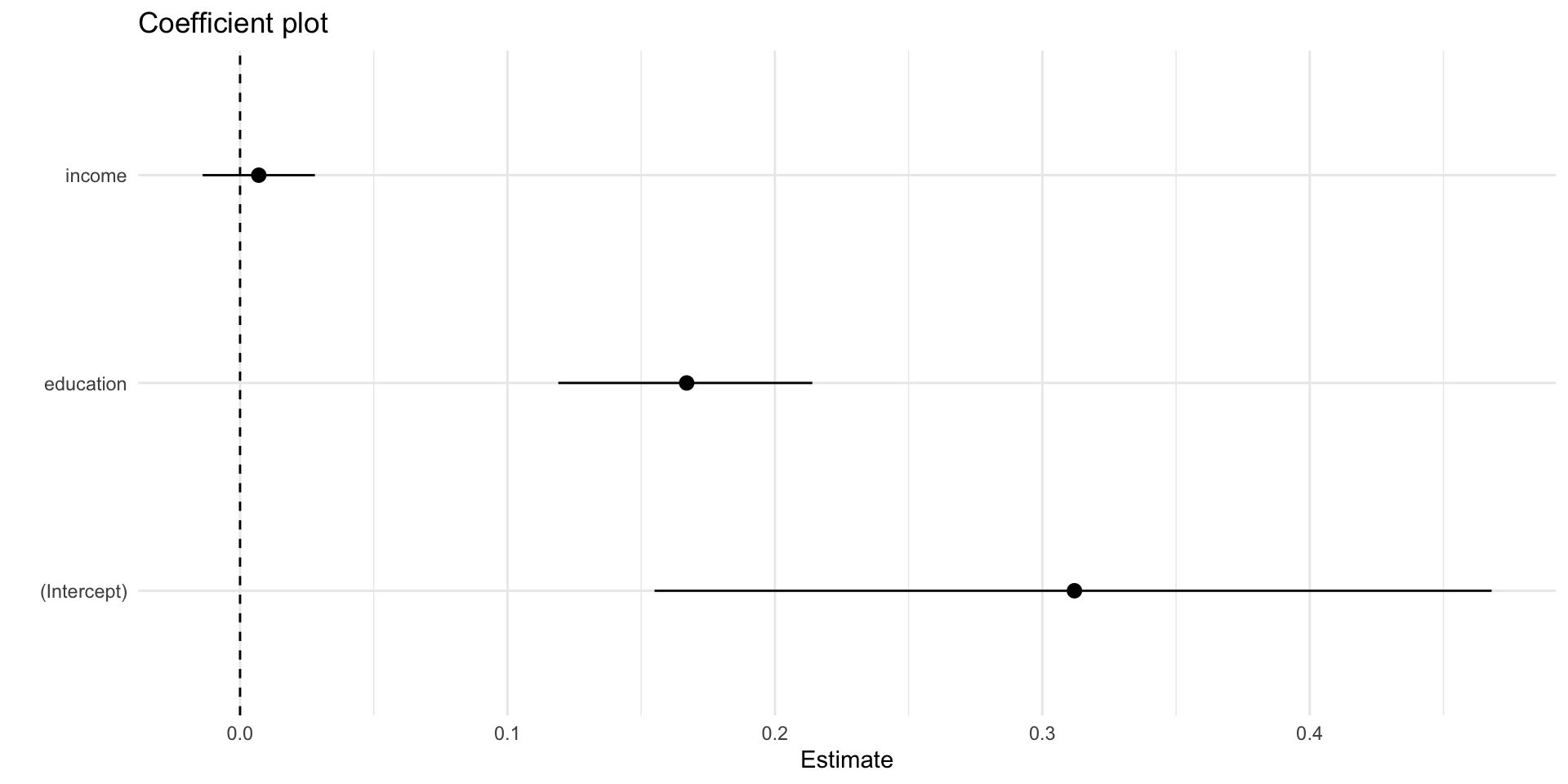
The estimate column are the regression coefficients, \(\beta\)
Recall, lm_robust() calculates these:
\[
\hat{\beta} = (X'X)^{-1}X'y
\]
Tip
\(\beta\)s describe substantive relationships between predictors (income, education) and the outcome (political participation)
coef(m1)
(Intercept) income education
0.311609712 0.007034253 0.166755964
X <-model.matrix(m1,data=df)y <-model.frame(m1)$dv_participationbetas <-solve(t(X)%*%X)%*%t(X)%*%ybetas
[,1]
(Intercept) 0.311609712
income 0.007034253
education 0.166755964
A unit increases in education is associated with about 0.16 more acts of political participation, while a unit increase in income is associated with 0.007 more acts of participation.
Note that both income and education are measured with ordinal scales
get_value_labels(df$educ)
No HS credential High school graduate Some college
1 2 3
2-year degree 4-year degree Post-grad
4 5 6
Such that it might be unreasonable to assume cardinality (going from a 1 to 2 is the same as going from a 3 to 4)
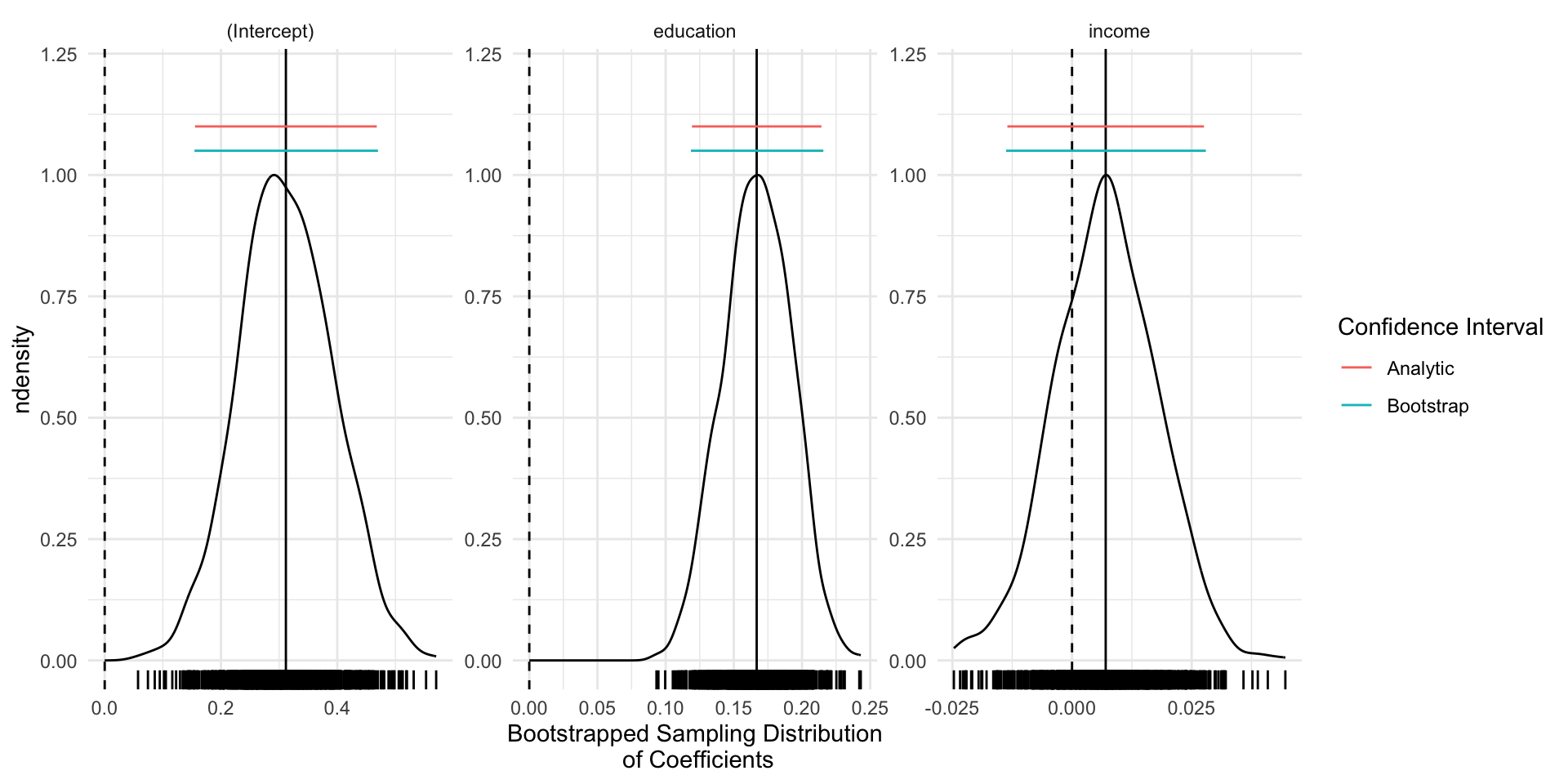
The main takeaway here is that for linear models, bootstrapped SEs and CIs are quite similar to those obtained via analytically (via math and asymptotic theory)
For common estimators and large samples, we’ll generally use analytic SEs (quicker)
For less common estimators (ratios of estimates), analytic estimates of the SEs may not exist. Bootstrapping will still provide valid SEs, provided we “sample from the sample, as the sample was drawn from the population”
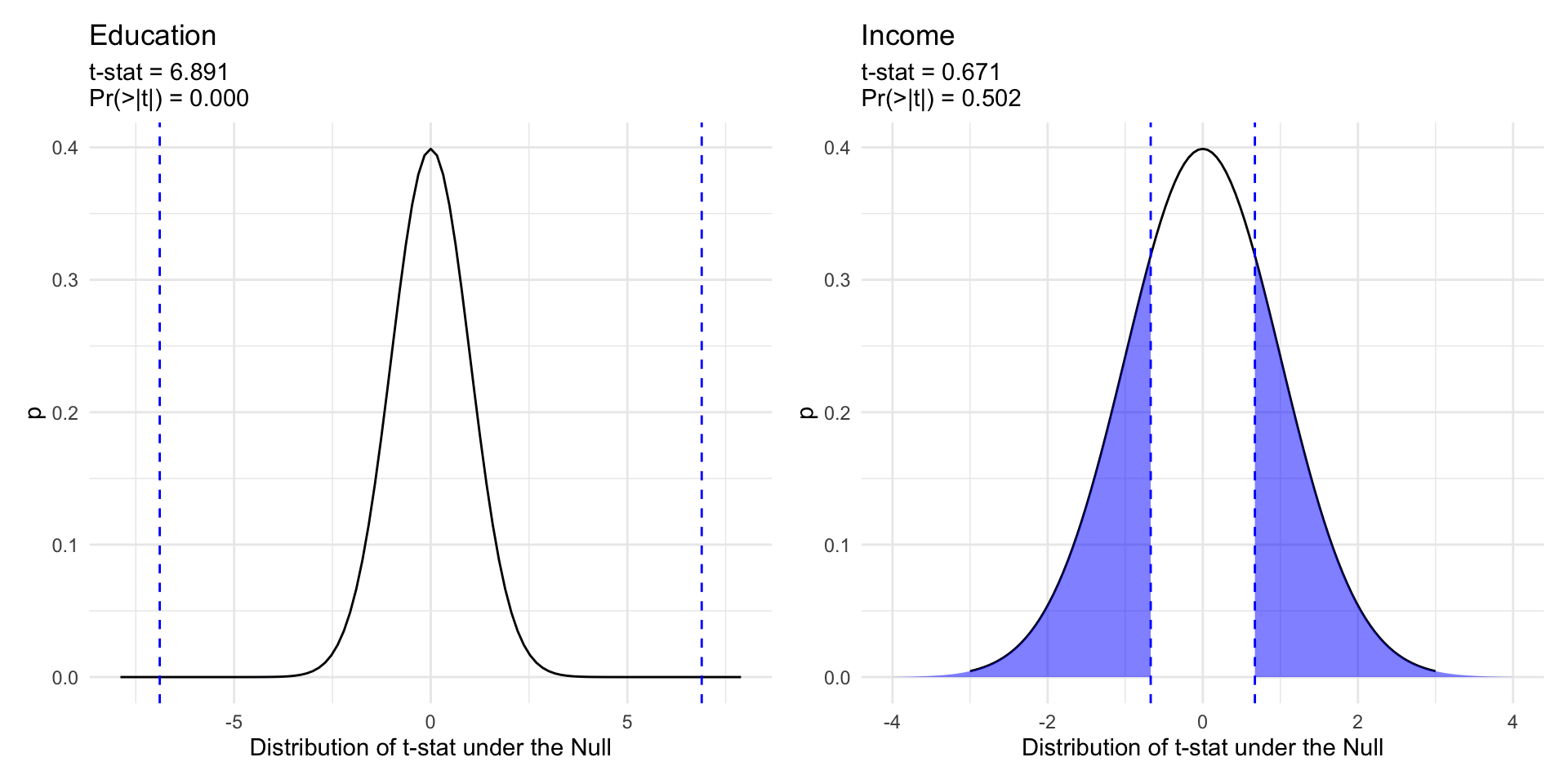
The test statistic (“t-stat”) reported by lm() and lm_robust() is our observed coefficient, \(\hat{\beta}\) minus our hypothesized value \(\beta\) (e.g. 0), divided by the standard error of \(\hat{\beta}\).
\[t= \frac{\hat\beta-\beta}{\widehat{SE}_{\hat{\beta}}} \sim \text{Students's } t \text{ with } n-k \text{ degrees of freedom}\] Which follows a \(t\) distribution – like a Normal with “heavier tails” (e.g. more probability assigned to extreme values)
The p-value for the coefficient on education is less than 0.05, while the p-value for income is 0.50.
If there was no relationship between education and participation (\(H_0:\beta_2=0\)), it would be quite unlikely that we would observed a test statistic of 6.89 or larger.
Similarly, test statistics as larger or larger than 0.671 occurs quite frequently in a world where there is no relationship (\(H_0:\beta_3=0\)) between income and participation.
Thus we reject the null hypothesis for education, but fail to reject the null hypothesis for income in this model.
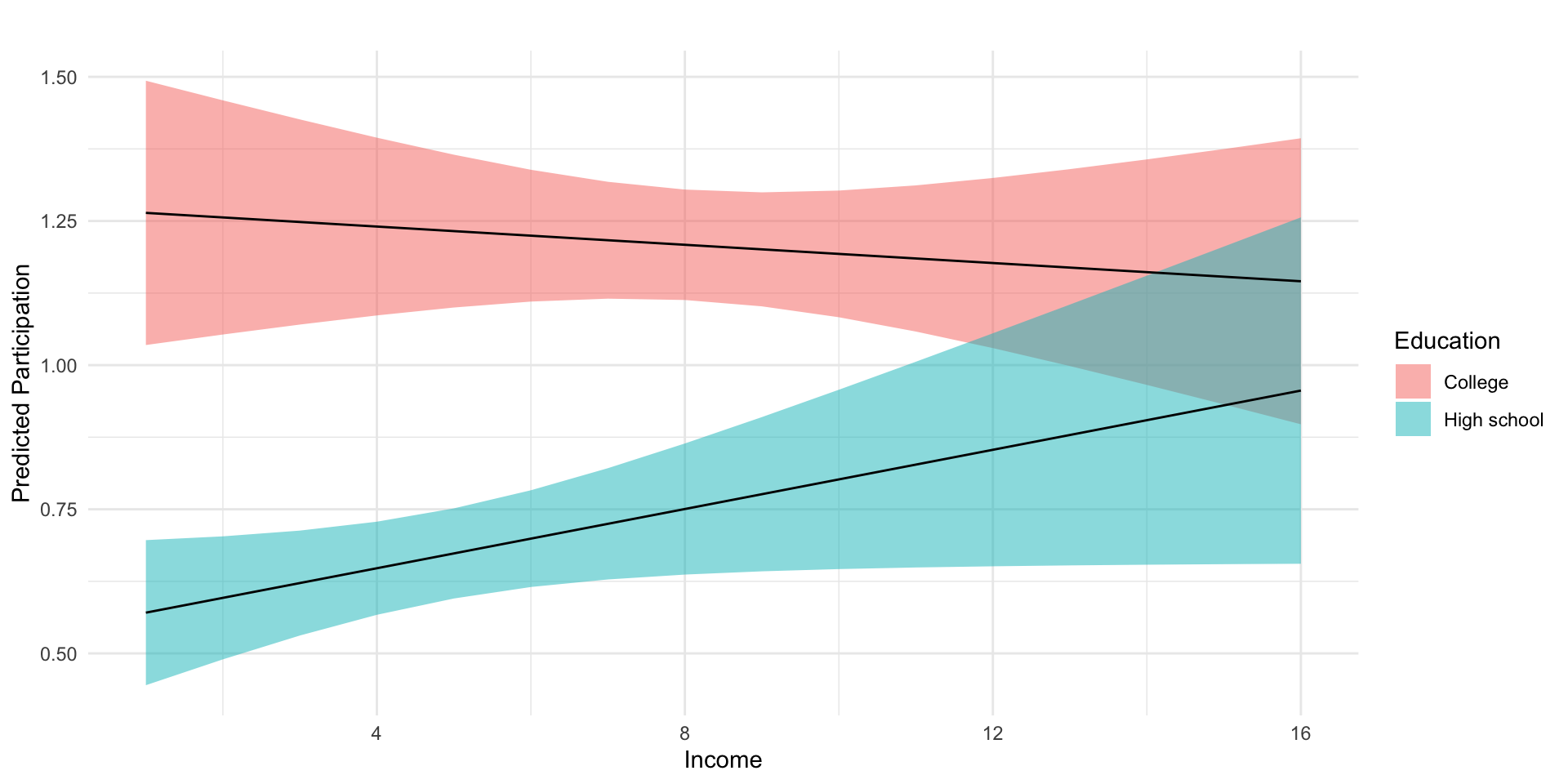
To help our interpretations we’ll produce plots of predicted values of participation, at varying levels of income and education.
# Fit modelm2 <-lm_robust(dv_participation ~ education*income, df)# Regression Tablem2_tab <-htmlreg( m2, include.ci = F,digits =3,stars =c(0.05, 0.10) )# Predicted values# Data frame of values we want to make predictions atpred_df <-expand_grid(income =sort(unique(df$income)),education =quantile(df$education, na.rm = T)[c(2,4)])# Combine model predictionspred_df <-cbind(pred_df, predict(m2, pred_df,interval ="confidence")$fit)# Plot predicted valuesfig_m2_pred <- pred_df %>%mutate(Education =ifelse(education ==2, "High school","College") ) %>%ggplot(aes(income, fit, group=Education))+geom_ribbon(aes(ymin = lwr, ymax = upr,fill = Education),alpha=.5)+geom_line()+theme_minimal()+labs(y ="Predicted Participation",x ="Income",title ="")
Statistical models
Model 1
(Intercept)
0.060
(0.151)
education
0.242**
(0.050)
income
0.048**
(0.024)
education:income
-0.011*
(0.006)
R2
0.042
Adj. R2
0.040
Num. obs.
1687
RMSE
1.286
**p < 0.05; *p < 0.1
Low income individuals with a college degree participate at significantly higher rates than individuals with a similar levels of income with only a high school diploma.
Alternatively, we might say that the college educated tend to participate at similar levels, regardless of their level of income, while income has a marginally positive relationship with participation for those without college degrees.
Note
Is this a causal relationship? What assumptions would we need to make a causal claim about the effects of education on participation?
Today, we examine the interaction models at the heart of the Grumbach and Hill’s claims
# Load dataload(url("https://pols1600.paultesta.org/files/data/cps_clean.rda"))# Recode datapresidential_elections <-seq(1980, 2016, by =4)cps %>%mutate(age_group =fct_relevel(age_group, "65+"),SDR =ifelse(sdr ==1, "SDR","non-SDR"),election_type =ifelse(year %in% presidential_elections, "General","Midterm"), ) -> cps# ---- m1: Simple OLS regression ----m1 <-lm_robust(dv_voted ~ sdr, data = cps,se_type ="classical",try_cholesky = T)# ---- m2: Simple OLS with robust standard errors ----m2 <-lm_robust(dv_voted ~ sdr, data = cps,se_type ="stata",try_cholesky = T)# ---- m3: Two-way Fixed Effects for State and Year ----m3 <-lm_robust(dv_voted ~ sdr,data = cps,fixed_effects =~ st + year,se_type ="stata",try_cholesky = T)# ---- m4: TWFE for State and Year and cluster robust SEs ----m4 <-lm_robust(dv_voted ~ sdr,data = cps,fixed_effects =~ st + year,se_type ="stata",clusters = st,try_cholesky = T)
Statistical models
Model 1
Model 2
Model 3
Model 4
(Intercept)
0.54787***
0.54787***
(0.00037)
(0.00038)
sdr
0.06159***
0.06159***
0.00671***
0.00671
(0.00110)
(0.00108)
(0.00185)
(0.01405)
R2
0.00157
0.00157
0.02845
0.02845
Adj. R2
0.00157
0.00157
0.02841
0.02841
Num. obs.
1988501
1988501
1988501
1988501
RMSE
0.49658
0.49658
0.48986
0.48986
N Clusters
49
***p < 0.001; **p < 0.01; *p < 0.05
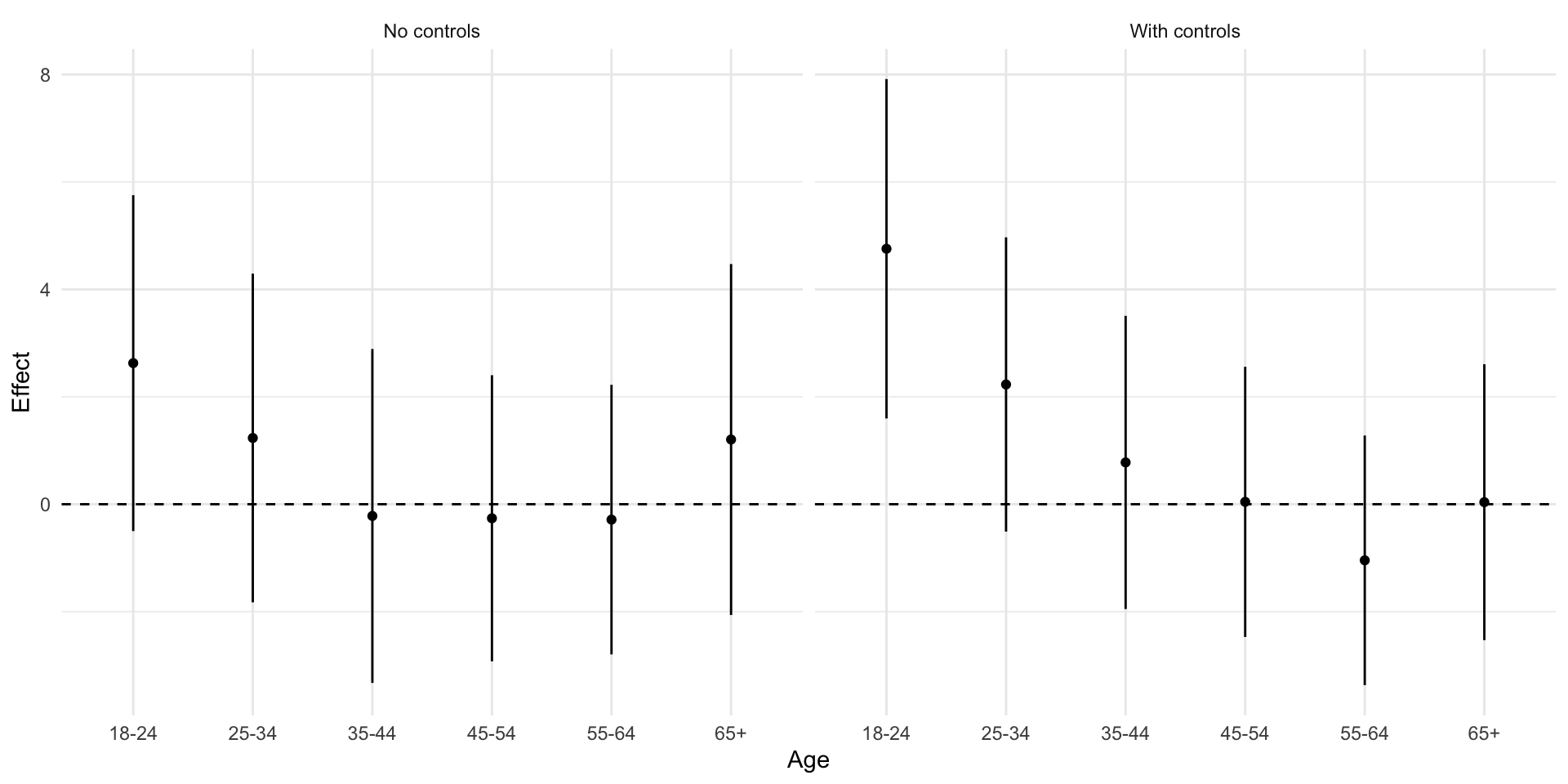
Fixed effects drastically reduce the overall size of the effect of SDR
Robust standard errors change our estimates of uncertainty.
Adjusting for:
Simple non-constant error variance \(\to\) no difference
Cluster \(\to\) non-significant result
Generally prefer conservative models (e.g. m4)
SDR and Age
Grumbach and Hill, however, are interested in a different question, namely, whether the effects of same day registration vary by age.
Formally, we we can describe these models using an interaction model:
\[
y_{ist} = \beta_0 + \overbrace{\alpha_s}^{\text{FE State}} + \underbrace{\gamma_t}_{\text{FE Year}} + \overbrace{\beta_1sdr_{st}}^{\text{ME of SDR for 65+}} + \underbrace{\sum_{k = 18-14}^{k = 55-64}\beta_{k} sdr_{st}\times age_{ist}}_{\Delta \text{ in ME of SDR for Age }} +\overbrace{X\beta}^{\text{Controls}}+\epsilon_{ist}
\] Where the marginal effect of SDR varies based on the age of the respondent.
Marginal Effects: General
The marginal effect of any variable in a multiple regression as the partial derivative of the outcome with respect to that variable.
\[
y_{ist} = \beta_0 + \overbrace{\alpha_s}^{\text{FE State}} + \underbrace{\gamma_t}_{\text{FE Year}} + \overbrace{\beta_1sdr_{st}}^{\text{ME of SDR for 65+}} + \underbrace{\sum_{k = 18-14}^{k = 55-64}\beta_{k} sdr_{st}\times age_{ist}}_{\Delta \text{ in ME of SDR for Age }} +\overbrace{X\beta}^{\text{Controls}}+\epsilon_{ist}
\]
Since 65+ is the excluded/reference category:
\[
\text{Marginal Effect of SDR for 65+} = \beta_1
\]
For 18-24 year olds the quantity of interest is the sum of:
\[
\text{Marginal Effect of SDR for 18-24} = \beta_1 + \beta_{sdr \times 18-24}
\]
The SEs of the Marginal effects is function of the variances and covariances of both \(\beta_1\) and \(\beta_{sdr\times age}\)
Let’s estimate the interaction models used by G&H and recreate figure 3 calculating the correct standard errrors for the interactions
m1gh <-lm_robust(dv_voted ~ sdr*age_group, data = cps,fixed_effects =~ st + year,se_type ="stata",clusters = st,try_cholesky = T )m2gh <-lm_robust(dv_voted ~ sdr*age_group +factor(race) + is_female + income + education, data = cps,fixed_effects =~ st + year,se_type ="stata",clusters = st,try_cholesky = T )# ---- Function to calculate marginal effect and SE of interactions ----me_fn <-function(mod, cohort, ci=0.95){# Confidence Level for CI alpha <-1-ci z <-qnorm(1-alpha/2)# Age (Always one for indicator of specific cohort) age <-1# Variance Covariance Matrix from Model cov <-vcov(mod)# coefficient for SDR (Marginal Effect for reference category: 65+) b1 <-coef(mod)["sdr"]# If age is one of the interactionsif(cohort %in%c("18-24","25-34","35-44","45-54","55-64")){# get the name of the specific interaction the_int <-paste("sdr:age_group",cohort,sep="")# the coefficient on the interaction b2 <-coef(mod)[the_int]# Calculate marginal effect for age cohort me <- b1 + b2*age me_se <-sqrt(cov["sdr","sdr"] + age^2*cov[the_int,the_int] +2*age*cov["sdr",the_int]) ll <- me - z*me_se ul <- me + z*me_se }if(!cohort %in%c("18-24","25-34","35-44","45-54","55-64")){ me <- b1 me_se <- mod$std.error["sdr"] ll <- mod$conf.low["sdr"] ul <- mod$conf.high["sdr"] }# scale results to be percentage points res <-tibble(Age = cohort,Effect = me*100,SE = me_se*100,ll = ll*100,ul = ul*100 )return(res)}## List of age cohortsthe_age_groups <-levels(cps$age_group)## Model 1: No controls## Estimate Marginal effect for each age cohortthe_age_groups %>% purrr::map_df(~me_fn(m1gh, cohort=.)) %>%# Add labels for plottingmutate(Age =factor(Age),Model ="No controls" ) -> fig3_no_controls## Model 3: Controls for Education, Income, Race,and Sex ## Estimate Marginal effect for each age cohortthe_age_groups %>% purrr::map_df(~me_fn(m2gh, cohort=.)) %>%# Add labels for plottingmutate(Age =factor(Age),Model ="With controls" ) -> fig3_controls## Combine estimates into data frame for plottingfig3_df <- fig3_no_controls %>%bind_rows(fig3_controls)## Recreate Figure 3fig3_df %>%ggplot(aes(Age, Effect))+geom_point()+geom_linerange(aes(ymin = ll, ymax =ul))+geom_hline(yintercept =0, linetype ="dashed")+facet_wrap(~Model)+theme_minimal() -> fig3
Statistical models
Model 1
Model 2
sdr
0.0120
0.0004
(0.0162)
(0.0128)
age_group18-24
-0.3518***
-0.4125***
(0.0061)
(0.0051)
age_group25-34
-0.2149***
-0.3198***
(0.0060)
(0.0040)
age_group35-44
-0.1026***
-0.2179***
(0.0063)
(0.0038)
age_group45-54
-0.0431***
-0.1450***
(0.0059)
(0.0038)
age_group55-64
0.0064
-0.0642***
(0.0047)
(0.0036)
sdr:age_group18-24
0.0142
0.0472***
(0.0108)
(0.0081)
sdr:age_group25-34
0.0003
0.0219**
(0.0137)
(0.0076)
sdr:age_group35-44
-0.0142
0.0074
(0.0162)
(0.0087)
sdr:age_group45-54
-0.0147
0.0001
(0.0120)
(0.0068)
sdr:age_group55-64
-0.0149
-0.0108
(0.0096)
(0.0062)
factor(race)200
0.0518***
(0.0081)
factor(race)300
-0.0548***
(0.0118)
factor(race)650
-0.1619***
(0.0305)
factor(race)651
-0.1784***
(0.0090)
factor(race)652
-0.1277***
(0.0188)
factor(race)700
-0.0916***
(0.0236)
factor(race)801
0.0130
(0.0110)
factor(race)802
-0.0233*
(0.0097)
factor(race)803
-0.0406
(0.0277)
factor(race)804
-0.0566
(0.0403)
factor(race)805
0.0548
(0.0291)
factor(race)806
-0.0432
(0.0520)
factor(race)807
-0.0486
(0.0574)
factor(race)808
-0.0593
(0.0473)
factor(race)809
-0.1125***
(0.0271)
factor(race)810
0.0169
(0.0340)
factor(race)811
-0.0932
(0.1396)
factor(race)812
-0.0474
(0.0891)
factor(race)813
-0.0445***
(0.0076)
factor(race)814
-0.0316
(0.1223)
factor(race)815
-0.1124
(0.0601)
factor(race)816
0.2548
(0.1910)
factor(race)817
0.1245
(0.1979)
factor(race)818
0.8195***
(0.0074)
factor(race)819
-0.0831
(0.1869)
factor(race)820
0.0325
(0.0592)
factor(race)830
-0.1871**
(0.0667)
is_female
0.0240***
(0.0017)
income
0.0093***
(0.0002)
education
0.0895***
(0.0016)
R2
0.0864
0.1707
Adj. R2
0.0864
0.1706
Num. obs.
1980510
1616508
RMSE
0.4748
0.4515
N Clusters
49
49
***p < 0.001; **p < 0.01; *p < 0.05
Why the differences?
Differences in how we calculated the SEs for marginal effects